
Site Reliability: удосконалюємо якість та надійність сервісів з використанням SLI/SLO/SLA
Підписуйтеся на Telegram-канал «DOU #tech», щоб не пропустити нові технічні статті
Be careful, today is not a good day to have a downtime! But 0.001% can be accepted
Привіт! Мене звати Тарас, я Operational Intelligence Engineer в EPAM Systems, залучений у наукову діяльність у Львівській політехніці і крім того AWS Educate Ambassador. Оскільки займаюсь моніторингом та аналітикою, часто доводиться робити різноманітні обчислення, пов’язані з перфоманс моніторингом та контролем надійності інфраструктури. Саме тому у статті хочу поділитись цим досвідом, певними особливостями, а також вказати на помилки, які часто допускають при визначенні та обчисленні Service Level Objectives (SLO).
Стаття буде корисною для:
- Розробників, системних інженерів, аналітиків;
- Менеджерів, які використовують або лише планують застосовувати SLO;
- Всіх зацікавлених у real-time data analysis та моніторингу.
У статті я б хотів зосередитись на наступних питання:
- Кому і для чого потрібні SLO;
- Наскільки (не)дешевим є Application Performance Monitoring (APM) & Site Reliability Engineering (SRE);
- Чому SRE з концепцією SLO стають такими «хайповими»;
- Як сучасний бізнес-світ отримує перші плоди цього інструменту;
- Шляхи теоретичної і практичної імплементації SLO.
Також на читачів чекає бонус:
- Mathematics behind SLO;
- Правильна і не дуже концепція для SLO/SLI/SLA;
- Робимо перфоманс моніторинг обчислювально дешевшим.

За останні декілька років все більше корпорацій та глобальних вендорів починають звертати увагу на концепцію Service level objectives, яка є важливим компонентом у APM & SRE.
Чому?
Дослідження показують, що чимало підприємств має близько 800 годин недоступності сервісу чи сайту на рік. Це понад 15 годин на тиждень — і витрати можуть бути неабиякими.
У перспективі можемо врахувати, що виробник у галузі Automotive втрачає $ 22 000 за хвилину downtime. Та якщо витрати невеличкого ентерпрайзу, ймовірно, не наближаються до цього, навіть втрата кількох сотень доларів на годину може мати істотний вплив на the bottom line.
Саме тому ключова ціль APM/SRE- це забезпечення менеджерів, аналітиків, розробників необхідною інформацією про інфраструктуру, її «життєздатність» і виміряти щастя користувача продукту.
Та найбільш цікавим і складним є питання чи можна зменшити відсоток downtimes за допомогою визначення і моніторингу SLO? Спойлер: і так, і ні.
Коротко про Service Level елементи
Враховуючи тенденцію до експоненціального зростання користувачів мережі Інтернет та й обсягів інформації загалом, виникає гостра потреба в утилізації цих же таки SRE/APM.
Google вважаються першими, хто розробили концепцію Site Reliability Engineering. Сама SRE визначається як дисципліна, яка включає аспекти інженерії програмного забезпечення
та застосовує їх до проблем інфраструктури та експлуатації. Основними цілями є створення масштабованих та високонадійних програмних систем.
Відповідно, якщо враховувати технологічні потреби і масштаб, на якому оперує Alphabet Inc, до якого входить Google, потреба у реалізації SRE-концепції стає більш чіткою та зрозумілою.
Цікавою та потенційно невід’ємною складовою перфоманс моніторингу стають практики, що забезпечують розробку доволі екзотичних і ключових елементів SLI > SLO > SLA.
Саме на цих складових та елементах ми зосередимось у статті. Адже SRE — це доволі широка тема, тому ми розглянемо лише цей аспект, пов’язаний з визначенням і обчисленням Service Level елементів.
Спільним для всіх цих елементів є зосередженість на сервісі: застосунок, система, інфраструктура тощо. Та між ними є чітке розгалуження і визначення:
- Service Level Objective (SLO) — ціль, яку потрібно дотримуватись, базується на внутрішньому документі, де визначені допустимі межі і пороги для конкретних індикаторів.
Приклад: 99.9% надійності веб-сайту; - Service Level Indicator (SLI) — метрика, яка використовується для того, щоб обчислювати SLO. Приклад: Failure rate, Latency, Response time;
- Service Level Agreement (SLA) — угода про те, який сервіс ми обіцяємо надавати користувачам. Приклад: 99% доступності сервісу.
На перший погляд, SLO й SLA є доволі схожі проте, зазвичай SLA є більш слабкою метою, ніж SLO. Це може виражатись у такій цілі: наприклад, SLA на доступність 99,9% протягом 1 місяця, тоді як внутрішнє SLO доступності 99,95%. SLA — це зазвичай обіцянка, яку ми даємо користувачам продукту.

Слід пам’ятати, що SLO стосується часу і зазвичай відповідає на такі запитання: Який відсоток часу X був здатний відповідати порогу Y індикатора Z?
Короткотермінові SLO є важливими для розробників, SRE команд, тоді як довготривалі SLO слугують для менеджменту організацій, перегляду цілей тощо.
Наприклад, якщо встановити 99.9% SLO, тоді загальний час, коли його можна порушувати є наступним:
- Протягом 30 днів — 43 хвилин;
- Протягом 90 днів — 129 хвилин.
SLI відповідає на питання: Які метрики контролюються? Що спостерігається?
Практика моніторингу SLI/SLO/SLA разом — це засоби управління інцидентами. Таким чином, завдяки SLO ці ж інциденти стають передбачуваним і значно простіше здійснювати їх менеджмент.
Мабуть, більшість із нас чули про популярність підрахунку на великих заводах кількості днів без нещасних випадків. У цьому є дещо схоже з SLO, тільки тут ми визначаємо бюджет часу і коштів, який можна дозволити на ці інциденти, які є критичними для бізнесу: downtimes, помилки, повільність, transaction timeouts тощо.

Тому SLO — це змога зменшити кількість інцидентів > зробити користувачів щасливими > збільшити кількість клієнтів і прибуток > забезпечити надійність + доступність інфраструктури.
«Хайп» навколо SLO та типові use-cases
SLO — це доволі популярний сьогодні тренд, і хороша новина у тому, що ентерпрайзи різної величини в захваті від цього. Why?
- Це слугує як так званий мотиваційний чинник, що дозволяє ставити перед собою ціль, досягати, збільшувати планку і знову досягати її;
- Виміряти щастя кінцевого користувача;
- Зрозуміти, що будь-яка система не є ідеальною, а технічна недоступність може бути допустимою;
- Моніторинг SLO дозволяє тримати руку на пульсі, розуміти на якому етапі вдосконалення інфраструктури ми є зараз, щоб покращити performance у майбутньому;
- SLO можна моніторити у real-time, а на ринку інструментів для цього більше, ніж достатньо. Від кольору до вибору.
«Ми досягнемо 99.99% надійності веб-сайту і подвоїмо прибуток удвічі» — цитати успішних людей, які вже застосовують SLO.
Реалізація моніторингу для SLO — це замкнене коло, над яким можна працювати вічно і дуже важливим є перший етап — правильно визначити SLI/SLO/SLA.
Припустимо у нас слабенька інфраструктура, проте наші очікування високі. Ми вважаємо, що вона спроможна справитись з високонавантаженими завданнями.
Згідно з SLO, наша система повинна бути доступною 95% часу, проте максимум, на що ми витягуємо — це 50%.
SRE команда починає багато кодити, намагається з’ясувати як би то підняти availability на +45% за 1 ніч, проте щось погано виходить.
У чому річ? Можливо, у нас погані інженери чи магнітні бурі давлять на серваки? Не думаю, проблема може бути в тому, ціль недостатньо реалістична на початковому етапі. Можливо, варто спробувати підняти інфру хоча б на
Другий етап потребує Data-інженерів, які повинні консолідувати дані, метрики, логи у єдине сховище для подальшого моніторингу.
Підключається команда аналітиків, яка розробляє інтерактивні дашборди, щоб можна було моніторити SLI/SLO/SLA.
Всі ми багато починаємо працювати, виділяємо ресурси, щоб SLO було досягнуто і був «нарешті фініш».
Спойлер: його не буде, бо...
Настане третій етап.
Прийшов час запитань та аналітики:
- Чи покращилися перфоманс і продуктивність?
- Що нам дало збільшення доступності інфраструктури?
- А кому потрібні ті SLO?
- Чи збільшився дохід?
- А користувачі щасливі?
Якщо всі (або ж 99.99%) щасливі, можемо реалізувати кінцевий етап
— перегляд цілей, використання і моніторинг нових SLI, удосконалення існуючих SLO & SLA, та повернення на перший етап.

Інструменти для SLO
Якщо звернути увагу на тенденції вендорів та продуктів, які пропонують рішення моніторингу, не складно помітити, що у більшість з них можливість визначати і моніторити SLO входить за замовчуванням або ж у преміум пакеті. До найбільш поширених, що пропонують вже готові рішення, належать:
- New Relic;
- Splunk;
- Datadog;
- AppDynamics;
- Smartbear.
Сьогодні на ринку засобів чимало, проте слід пам’ятати, що це лише інструмент, а яким чином ми досягатимемо результатів — залежить від нас.
Стає очевидним, що для побудови SRE моніторингу немає обмежень і використовувати можна whatever you want. У випадку великого підприємства, яке може собі дозволити гнучке і масштабне рішення існує Splunk/New Relic. Якщо ж коштів не вистачає, але хочеться скуштувати той SRE, слід звернути увагу на open-source (Grafana, Elasticsearch, jssonnet). Головне — це бажання і трішки часу на імплементацію рішення.
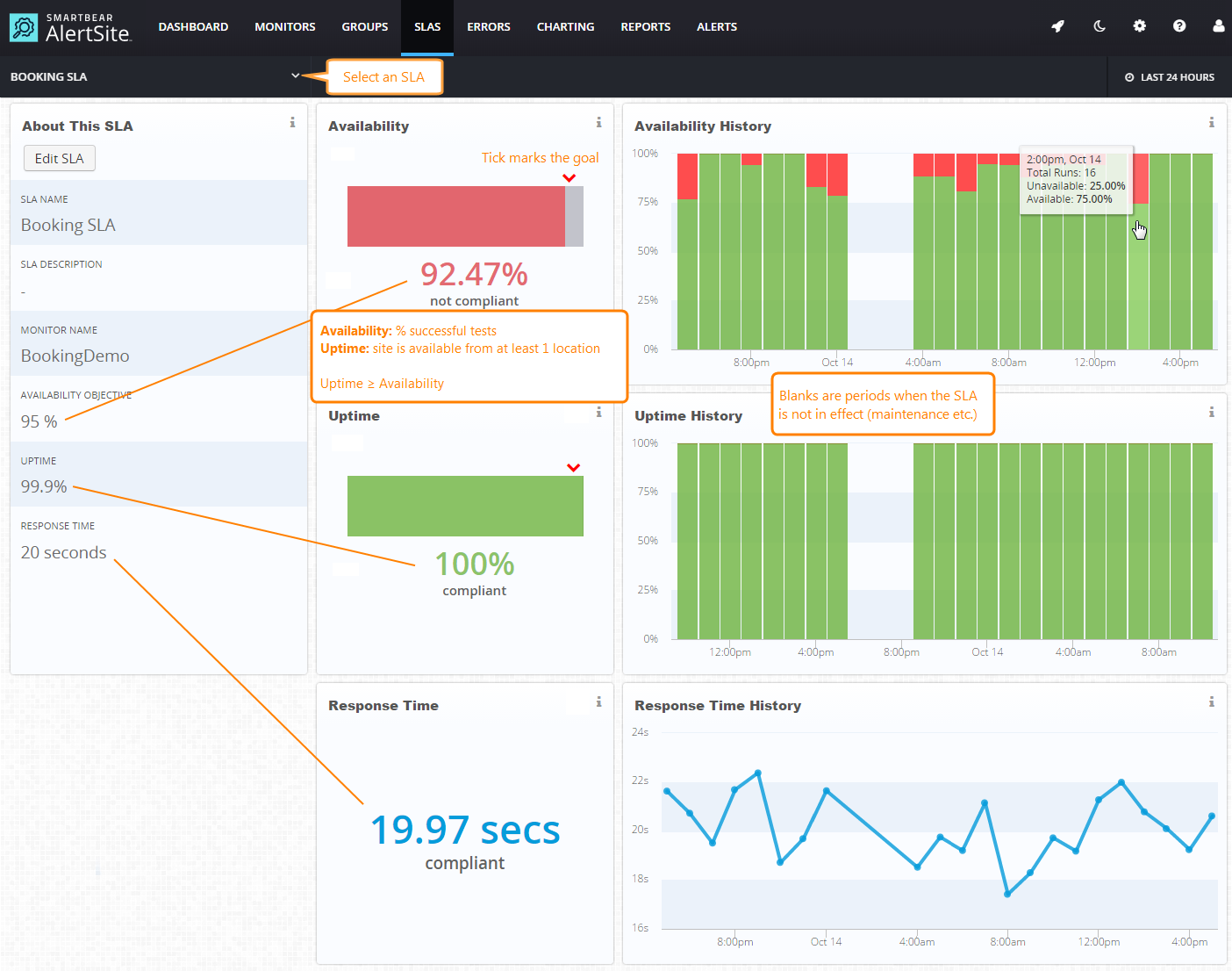
SLO dashboard у сервісі Smartbear
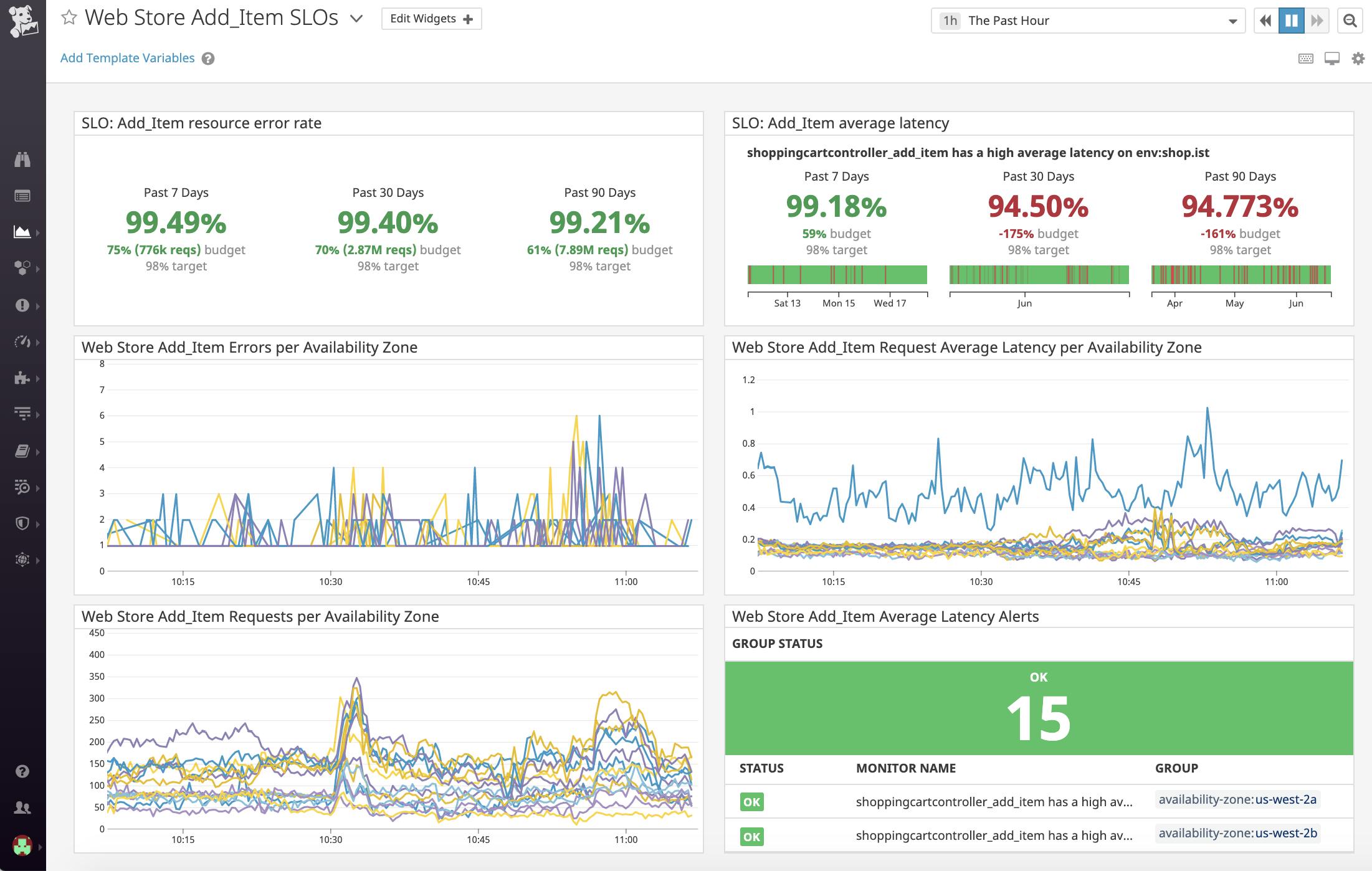
SLO dashboard у сервісі Datadog
Використання крутих інструментів, де всі обчислення проходять у background і від користувача майже нічого не потрібно — погодьтесь, звучить досить привабливо.
Саме тому чимало рішень для SLI/SLO/SLA потреб є open-source. Хорошим поєднанням можна вважати Elasticsearch, Logstash, Kibana (ELK Stack), яке надасть чимало можливостей.
Крім того, Prometheus як інструмент збору метрик, а Grafana для візуалізації теж непогана альтернатива.
Як не крути, навіть за допомогою R-дашбордів чи Python можна здійснювати моніторинг різноманітних індикаторів. Все залежить від наявності ресурсів, бюджету та очікуванням. Взявши до уваги ці чинники, можна обирати найкращий для конкретної бізнес-проблеми інструмент.
Що можна обчислювати для SLO моніторингу?
Метрики, KPIs, Індикатори
Визначившись з інструментом, який ми будемо використовувати, слід переходити до збору даних та аналітики.
Очевидно, для того, щоб здійснювати моніторинг повинен існувати набір метрик за допомогою яких ми можемо оцінювати якість роботи систем та застосунків.
Для цього є Service Level Indicators. Вони можуть бути традиційними (CPU/Memory Usage, Latency) та користувацькі. У моєму досвіді бували випадки, коли потрібно розробити індикатор, який буде дуже специфічний для певного застосунка і тоді він матиме більше користі, ніж будь-яка традиційна метрика. Проводилось дослідження даних,
потреб замовника і пропонувались різноманітні специфічні метрики. Саме завдяки такому індикатору вдалось покращити observability близько на 24%.
Та найбільшу цінність SLO приносить у моніторингу Availability та Reliability. Це ключові метрики, але не єдині.
Увага! Обидві метрики дуже важливі, але різні, тому що певне обладнання може бути доступним, але не надійним.
Наприклад, сервер, який падає на 6 хвилин щогодини. Це означає доступність 90%, але надійність менша, ніж 1 години, що не дуже прекрасно.
Availability чи доступність — відсоток часу, коли система є активною і працює, порівняно із загальним заплановами часом роботи. Нижче наведено формулу:
Доступність (%) = (Час активної роботи/Очікуваний час роботи) x 100%
Нехай очікуваний час роботи сервісу — 24 години на добу, але через об’єктивні причини — він працює лише 23 години. Таким чином Availability становить 95.83%.
Reliability чи надійність кількісно відображає ймовірність активної роботи інфраструктури за призначенням без перебоїв або помилок, вимірюватись може як тривалість,
так і у вигляді ймовірностей чи відсотків.
Надйіність = Total uptime / Number of breakdowns
Reliability корелює з іншою метрикою — MTBF (Mean Time Between Failures).
Припустимо, що сервер працює 10 годин протягом 10 днів, за цей період часу двічі він був недоступний. Після 25 годин роботи, його вдалось полагодити за 3 години, після чого він був знову доступний аж 22 години (майже доба!) і знову сталася помилка, через яку сервер лежав ще 4 години. Все стало на свої місця і сервер пропрацював ще 46 годин.
MTBF = (25 годин + 22 годин + 46 годин) / 2 помилки = 93 годин / 2 помилки = 46.5 годин.

Також ключовими є метрики, як Success & Failure rates, які показують відсоток успішних чи невдалих запитів.
Моніторинг тривалості
Досить поширеною і важливою вважається такий індикатор як Latency — час, який йде на опрацювання запиту. Відповідно, Latency теж можуть успішно застосовуватись як SLO.

Latency вказує скільки часу потрібно користувачу, щою отримати інформацію, яку він запитує. І одразу виникає декілька питань:
1. Що вважати початком запиту, а що кінцем, щоб отримати latency?
У багатьох джерел може бути різноманітне визначення Latency.
Прийнято вважати, що початком — є час, коли користувач надіслав запит, а завершенням — час, коли користувач отримав відповідь від сервера.
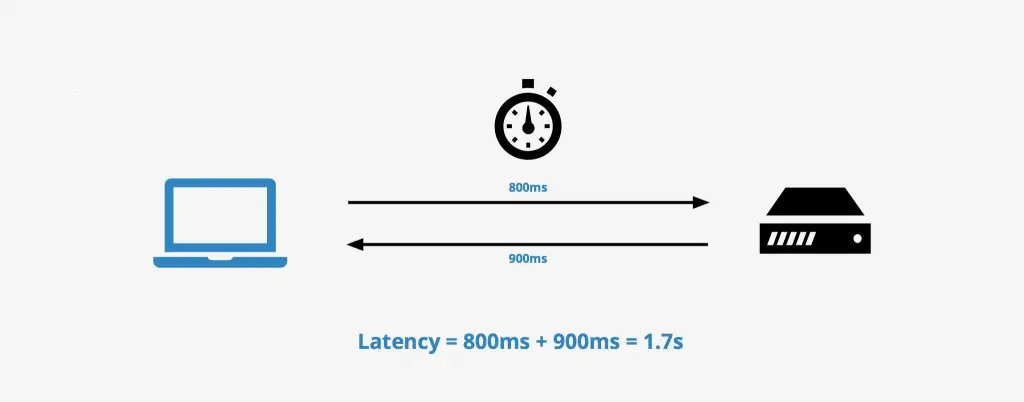
2. Що якщо проблема на стороні користувача, а не на стороні сервера?
Client/Server-side errors — це важливий компонент, який у моніторингу визначається за допомогою HTTP статус-кодів, вивченню логів.
У кращому випадку рекомендується збирати різноманітні SLI, які корелюють з Latency: transaction time, backend time тощо, які дозволяють визначити скільки
часу треба серверу чи окремому компоненту для опрацювання запиту. Таким чином є можливість здобути більше інформації і якісніше її моніторити.
3. Яким чином визначити чи швидке у системи Latency?
Знаходимо співвідношення запитів де Latency менше за встановлений поріг і всіх запитів. Результат відображатиметься у відсотках.
4. Чи є ефективним саме по собі Latency як SLI?
Достатньо ефективне, проте може бути удосконалене за допомогою кореляції з іншими метриками.
5. Що я можу ще обчилювати завдяки Latency?
Цінність цієї метрики ще й у тому, що дозволяє визначити User satisfaction level або ж Apdex Score.
Отож, індикаторів, які можна застосовувати доволі багато, при потребі можна розробляти користувацькі метрики, щоб здобути більше інсайтів.
Різноманітні показники роботи інфраструктури та застосунків є важливими джерелами інформації під час налагодження та дебагінгу систем на етапі тестування і продакшн.
Тому здійснення їх моніторингу та обчислення SLO є доволі важливим для висконовантажених сервісів.
Приклад обчислення SLO на 30 днів заздалегідь
Для обчислення SLO потрібні:
- Метрика (SLI);
- Ціль короткотривала (SLO);
- Ціль довготривала (SLO або SLA);
- Розуміння можливостей інфраструктури.
У цьому прикладі меторикою або SLI є Latency. Цілі — це і є SLO, які ми розробляємо для себе, організації, і SLA — ціль, що ми обіцяємо досягати для користувачів.
Короткотривала ціль — 95% запитів протягом 5 хвилин повинні бути менші або дорівнювати 300 мілісекунд.
Довготривала ціль — короткотривала ціль повинна бути дотриманою у 99% випадках протягом 30 днів.
Дане обчислення SLO є не дуже дешевим, оскільки порівнюється кожен запит за 5 хвилин протягом 30 днів. Пізніше ми розглянемо яким чином здешевити це обчислення! :)

Визначаємо Error Budget
Уявімо ситуацію, коли ми хочемо не просто відобразити SLO, його значення у відсотках, але побачити скільки «провтиків» чи errors наша система може допустити.
Для цього є хороший підхід із застосуванням Error Budget.
Кожне SLO має окремий Error Budget, який визначається як 100% мінус (-) ціль для певного SLO. Наприклад, за останній тиждень було 1,000,000 запитів до API-сервера.
Success rate, згідно з SLO, повинен бути 99% > 100% — 99% = 1% або 10,000 помилок. Відповідно, це значення відображає скільки зафейлених запитів ми можемо собі дозволити через недоступний back-end, відсутність з’єднання з сервером та інші причини.

Безпечний шлях для швидких і дешевих обчислень
Для ефективних та інформативних SLO використовуються дані за останні 30 днів. Якщо через систему проходить щонайменше 10 000 запитів за годину, то за місяць виходить ~7,2 мільйонів. Досить багато, особливо, коли ми знаходимо медіану тривалості запиту для
І до цього додам ще трішки операторів порівняння та простих математичних функцій типу сума.
Опрацьовувати кожен запит на одному дашборді, де є декілька графіків стає дуже дорого і повільно.
Як рішення, можна застосувати так звані summary indexes. У багатьох APM-інструментах вони є доступними і доволі просто утилізуються.
Наприклад, у Prometheus — це Recording Rules, а у Splunk так і називається — Summary Indexing (а ще є Accelerated data model), тоді як ELK пропонує Data rollups.

Підсумкова індексація дозволяє здійснювати швидкий пошук у великих наборах даних, розподіляючи витрати на обчислювально дорогий запит.
Береться невелика підмножина даних, що «раниться» раз на встановлений інтервал. Результат зберігається вже як метадані або агрегація.
Алгоритм дій простий:
- Розробити запит з необхідною метрикою для SLO-обчислень;
- Встановити інтервал як часто повинна вираховуватись метрика;
- Використовувати лише агреговане значення;
- Насолоджуватись результатом.
Висновки
Принади застосування SLO
Service Level Objectives — це інструмент, який при правильному застосування дозволяє принести багато плодів, а саме:
- Збільшити доступність та надійність інфраструктури;
- Зробити кінцевих користувачів продукту щасливішими, а також розуміти їхні потреби;
- Створити стимул для постійного вдосконалення;
- Покращити ефективність процесів розробки;
- Налагодити моніторинг, щоб здобувати якомога більше інсайтів.
А ще, SLO — легкий у застосуванні інструмент, його реалізація є цікавою, а також корисною, бо:
- простіше керувати ризиками пов’язаними з інфраструктурою;
- реалістично оцінювати роботу певних застосунків;
- забезпечити взаємовідповідальність між учасниками команди.
Недоліки SLO
Суттєвим недоліком SLO може бути надмірне зосередження на певних метриках та індикаторах, і цілковита або часткова байдужість до інших, не менш важливих.
Наприклад, уявіть ресторан, який завжди відкритий, але в ньому є жахлива їжа та обслуговування. Тобто:
availability = 100%, user satisfaction = 0%Або той, хто пропонує класну їжу та високий рівень обслуговування, але відкритий лише на одну годину, раз на тиждень. Знову ж таки:
Availability = 0.5% (1 година / 24 години * 7 днів), user-satisfaction = 99%Жоден з них не є оптимальним.
Якщо ми не дотримуємось наших SLO та SLA уважно, ми можемо або піддавати себе зайвому ризику, або давати пусті обіцянку своїм клієнтам і користувачам, що фактично нічого не означає.
Справжній шлях до успіху полягає у встановленні якісних SLA практик та їх дотриманні.
Мабуть, ми очікуємо, що компанії, які пропонують високонавантажені сервіси і продукти, як ось Google, Netflix, Gmail, AWS чи Facebook мають ціль — 100% Availability та успішно їх дотримуються. Проте, жодне правильно визначене SLO не може бути задоволене весь час.
Адекватно визначена ціль для онлайн-сервісу завжди менша, ніж 100%.
Думка автора
Та кому воно треба
Ми спостерігаємо, як змінюються старі і розробляються нові інфраструктурні рішення, адже доступність і надійність сайтів для бізнесу стає майже лінійною з доходами і прибутком.
Проте, SLO — це не є щось таке, що можна створити і забути. Згідно з Storage Switzerland, протягом 10 років застосування, 60% Service-level objectives залишаються без змін,
25% — вимагають незначних модифікацій, тоді як 15% потребують значного вдосконалення і перегляду.

Service level objectives для бізнесу — це:
- можливість визначити внутрішні цілі для міцної та надійної інфраструктури;
- здобути довіру клієнтів та користувачів;
- створити міцний мотиваційний чинник для подальшого вдосконалення системи/застосунка/сервісу.
Найважливішим є збирання необхідних метрик, грамотне визначення цілей і забезпечення їх виконання перед користувачами.
Services Need SLOs
Покликання
Більше корисної інформації про SRE у Google, які застосовуються і за його межами, можна знайти за наступними посиланями
10 коментарів
Додати коментар Підписатись на коментаріВідписатись від коментарів